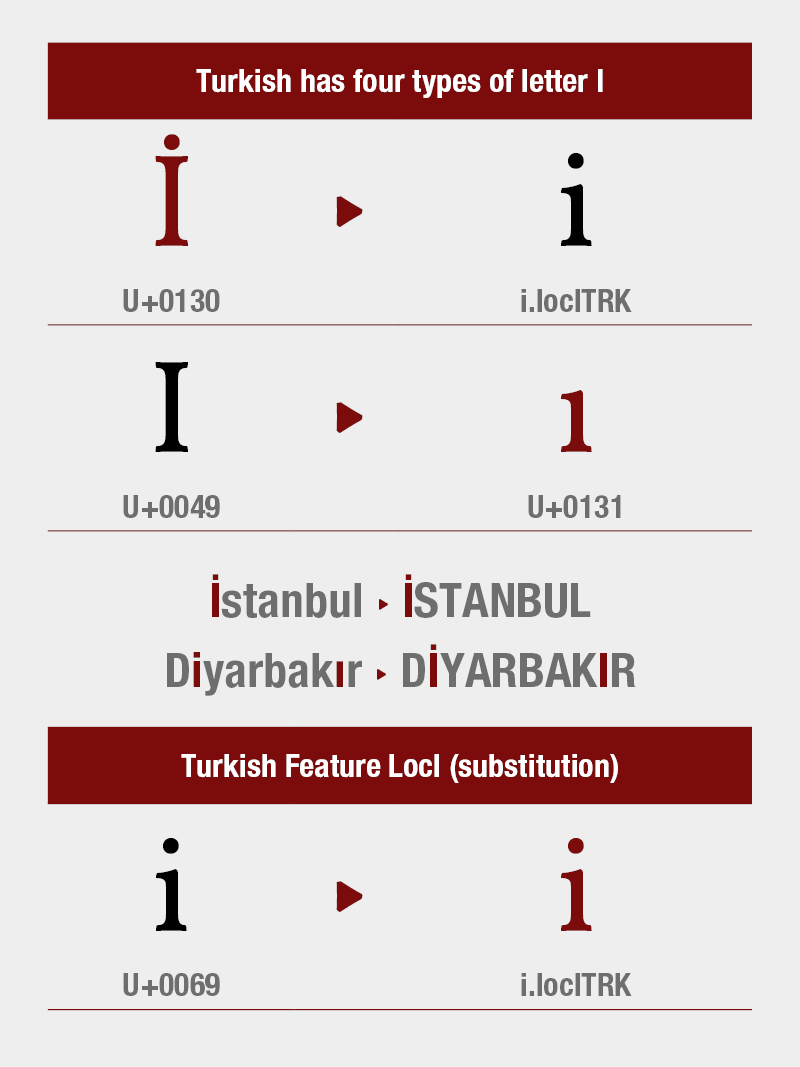
Turkish Feature Locl
Please click the picture to see it enlarged.
OpenType code
feature locl {
script latn;
language TRK exclude_dflt;
sub i by i.loclTRK;
} locl;
The same code is used for several other Turkish languages as Azeri and Crimean Tatar.
feature locl {
script latn;
language TRK exclude_dflt; # Turkish
lookup I_TURKISH {
sub i by i.loclTRK;
} I_TURKISH;
language AZE exclude_dflt; # Azeri
lookup I_TURKISH;
language CRT exclude_dflt; # Crimean Tatar
lookup I_TURKISH;
} locl;
Turkish language
Dotted İi and dotless Iı are separate letters in Turkish (TRK) language. They are separate letters in Azeri (AZE), Crimean Tatar (CRT) and Kazakh (KAZ) languages also.
The dotless I, I ı, denotes the close back unrounded vowel sound (/ɯ/) in Turkish and Azeri languages. Neither the upper nor the lower case version has a dot.
The dotted İ, İ i, denotes the close front unrounded vowel sound (/i/) in Turkish and Azeri languages. Both the upper and lower case versions have a dot.
Examples
İstanbul /isˈtanbuɫ/ (starts with an i sound, not an ı).
Diyarbakır /dijaɾˈbakɯɾ/ (the first and last vowels are spelled and pronounced differently)
In contrast, the letter j does not have this distinction, with a dot only on the lower case character: J j.
In normal typography, when lower case i is combined with other diacritics, the dot is generally removed before the diacritic is added; however, Unicode still lists the equivalent combining sequences as including the dotted i, since logically it is the normal dotted i character that is being modified.
Most Unicode software uppercases ı to I and lowercases İ to i, but, unless specifically configured for Turkish, it lowercases I to i and uppercases i to I. Thus uppercasing then lowercasing, or vice versa, changes the letters.
In the Microsoft Windows SDK, beginning with Windows Vista, several relevant functions have a NORM_LINGUISTIC_CASING flag, to indicate that for Turkish and Azerbaijani locales, I should map to ı and i to İ.
In the LaTeX typesetting language the dotless ı can be written with the backslash-i command: \i. The İ can be written using the normal accenting method (i.e. \.{I}).
Dotless ı (and dotted capital İ) is handled problematically in the Turkish locales of several software packages, including Oracle DBMS, PHP, Java (software platform), and Unixware 7, where implicit capitalization of names of keywords, variables, and tables has effects not foreseen by the application developers. The C or US English locales do not have these problems. The .NET Framework has special provisions to handle the ‘Turkish i’.
Many cellphones available in Turkey (as of 2008) lack a proper localization, which leads to replacing ı by i in SMS, sometimes severely distorting the sense of a text. In one instance, a miscommunication played a role in the deaths of Emine and Ramazan Çalçoban in 2008. A common substitution is to use the character 1 for dotless ı. This is also common in Azerbaijan (see also translit), but the meaning of words is generally understood.
See more at WIKIPEDIA
Ligatures
By substituting i with i.loclTRK (identical to the i in appearance) for Turkish, you automatically suppress the fi ligature as a side effect, which is the proper way to handle it in Turkish.
Note that feature locl must be inserted before feature liga in the list of features.
Because in Turkish, you have separate case conversions (i -> İ, ı -> I) which are different from other languages, and case conversion also applies to the smcp feature, and because the visual distinction between i and ı should be maintained even in ligatures, and some designers tend to blur this distinction in f_i ligatures by folding or merging the dot, this is how you’d deal with it in an OT font.
1. You make an i.loclTRK glyph which is identical to i but it’ll be treated differently in subsequent features.
2. You have a special languagesystem latn TRK in which you only perform one substitution: i -> i.loclTRK in the “locl” feature.
3. From now on, you know that in the Turkish context, one of two glyphs will appear: i.loclTRK (with a dot) or dotlessi (without a dot).
4. In features such as liga, you can safely do things like f i -> f_i and you don’t need to think about special lookups for “ligatures with an i” and ligatures “without an i”.
5. Similarly, in the smcp feature, you can safely do i -> I.sc (dot vanishes), i.loclTRK -> Idotaccent.sc (dot stays), dotlessi -> I.sc (not dot at all).
For most languages, the dotted i’s uppercase or smallcaps counterpart is a dotless I but for Turkish, the dot needs to stay. So without i.loclTRK, you’d need special treatment whenever “i” is involved in a feature.
With “i.loclTRK”, you disambiguate the normal “i” and the Turkish “i” early (locl is among the first features to be processed), and all your subsequent features can be written in a simple way.
Of course i.loclTRK is not always required. If your font doesn’t have small-caps and your f_i ligatures are drawn so that the dot over the i is fully visible (because you shorten the f’s tail rather than elongate it), you shouldn’t have a TRK languagesystem or i.loclTRK.
f_i ligatures can be used in Turkish but only if those ligatures don’t blur the visual distinction between the dotted and the dotless i in such a ligature.
Localisation for Turkish in Feature Liga
feature liga {
script latn;
sub f f i by f_f_i;
sub f i by fi;
lookup NOFI {
sub f f l by f_f_l;
sub f f by f_f;
sub f l by fl;
sub f f j by f_ f_ j;
sub f j by f_ j;
} NOFI;
language TUR exclude_dflt;
lookup NOFI;
} liga;
Türkçe | Turkish language
Türkçe ya da Türk dili, Güneydoğu Avrupa ve Batı Asya’da konuşulan, Türk dilleri dil ailesine ait sondan eklemeli bir dil. Türk dilleri ailesinin Oğuz dilleri grubundan bir Batı Oğuz dili olan Osmanlı Türkçesinin devamını oluşturur. Dil, başta Türkiye olmak üzere Balkanlar, Ege Adaları, Kıbrıs ve Orta Doğu’yu kapsayan eski Osmanlı İmparatorluğu coğrafyasında konuşulur. Ethnologue’a göre Türkçe, yaklaşık 83 milyon konuşuru ile dünyada en çok konuşulan 20. dildir. Türkçe Türkiye, Kıbrıs Cumhuriyeti ve Kuzey Kıbrıs’ta ulusal resmî dil statüsüne sahiptir.
Türkçe, diğer pek çok Türk dili ile de paylaştığı sondan eklemeli olması ve ünlü uyumu gibi dil bilgisi özellikleri ile karakterize edilir. Dil, tümce yapısı açısından genellikle özne-nesne-yüklem sırasına sahiptir. Almanca, Arapça gibi dillerin aksine gramatik cinsiyetin (erillik, dişilik, cinsiyet ayrımı) bulunmadığı Türkçede sözcüklerin bir kısmı Arapça, Farsça ve Fransızca gibi yabancı dillerden geçmedir. Ayrıca Azerice, Gagavuzca ve Türkmence gibi diğer Oğuz dilleri ile Türkçe yüksek oranda karşılıklı anlaşılabilirlik gösterir.
Türkçe 1928’de Atatürk önderliğinde gerçekleştirilmiş Harf Devrimi’nden beri Latin alfabesi ile yazılır. Standart Türkçedeki imla kuralları Türk Dil Kurumu tarafından denetlenir. İstanbul Türkçesi olarak da adlandırılan İstanbul ağzı, Türkçenin standart formudur ve Türkçe yazı dili bu ağzı temel alır. Bununla birlikte Güneydoğu Avrupa ve Orta Doğu’da çeşitli Türkçe şiveleri bulunur ve bu şiveler İstanbul Türkçesi ile çeşitli sessel farklılıklara sahiptir.
Further Readings
John Cowan: Resolving dotted and dotless “i”
Microsoft Docs: The Turkish Example
TypeDrawers: What is i.latnTRK
Glyphs: Localize Your Font: Turkish i
Tex Texin: Internationalization for Turkish: Dotted and Dotless Letter “I”
Wikipedia: Dotted and dotless I
Remarks
![]()
Stefan Peev is a graphic designer and typographer from Bulgaria.