Vedran Eraković, Source: Tipometar
Translation into English: Vesna Janković

Many users of text editing software noted a problem that appears when in text they have Cyrillic cursive letters т, п, г, д. These are Russian forms which were introduced by the reforms of Peter the Great. We developed other variations of these letters and because of that Russian forms should not appear in our Cyrillic texts. They differ from the standard form of our literature script which influence legibility as well as the graphic outlook of edited text. Despite this, the Russian letterforms are often to be found in our type and one of the reasons being lack of knowledge: many people are indifferent as far as the outlook of the faces they use and they do not know the difference between our and Russian forms. Other reason is of technical nature, for the Cyrillic forms originating from abroad, including Unicode fonts used at Internet, contain only Russian letterforms and consequently, the one using them often does not have a choice.
Today, there are Open Type Pro fonts, based on Unicode, which resolve this in some way, but many people simply neither know the possibilities of Open Type fonts nor the possibilities of the software enabling work with them.
The first computers were aimed at English speaking population which means that only the use of English alphabet was considered with few additional characters which all together made 128 characters in font. That was the first ASCII (American Standard Code for Information Interchange) standard, presented in 1967. With time this group of characters was enlarged to 256, with 128 new positions being used for additional characters.
To make support for more languages, the codepages were made consisting of 256 characters such as Latin I (ISO-8859-I) for Latin letters of western Europe, then Latin2 (ISO-8859-2) and Windows-1250 for Latin letters of eastern Europe such as our Latin script, Windows-1251 for Cyrillic… etc. The basic problem with these codepages is that for each codepage a separate font has to be made. Consequently, they started thinking of multibyte entry which would include all characters for all languages within one font and thus Unicode was made in 1991. There are several versions of Unicode and basic version of UCS-2 which uses two bytes for entry which makes 65536 characters thus including almost all languages of the world. The Unicode Consortium, with its seat in California, is one of the two organizations which develop Unicode standard and each organization or individual can become its member in case they are willing to pay for the membership. Almost all important companies having some interest in that field are the members (Adobe, Microsoft, IBM, Apple, HP…)
In Unicode each character is represented by four digits hexadecimal number (e.g. U+0065 for small Latin letter e) So each character has its unicode position and name and a software which supports Unicode recognizes these codes and presents exact characters for, as to avoid confusion, there is a universal agreement which code represent which character. The letters belonging to the same language are usually set in zones i.e. blocks and Cyrillic is in the range from U+0400 to U+052F. The characters in the range from U+0400 to U+045F are from ISO-8859-5 charset, old Cyrillic letterforms which are not used in modern texts are in the range from U+0460 to U+0486 and at positions from U+048A to U+052F are additional characters for different languages which are written in Cyrillic. Some letters are not defined by one character but are acquired by combination of two characters such as the letters with diacritics when a letter character is added diacritic one.
In the mid eighties ECMA (European Computer Manufacturers Association) designed ISO-8859 series, and their Cyrillic codepage ISO-8859-5 is made to keep compatibility with charsets made by the Russian GOST (государственный стандарт i.e. state standard) by using unused code points to add characters for other Cyrillic letters including ours. When Unicode was designed, the characters and their positions were taken over from already existing codepages. Thus for Cyrillic range in Unicode the mentioned charset ISO-8859-5 established in 1988 was used in which Russian letters were basic ones and so our variants of cursive letters did not have their code points in Unicode table. Unicode organization accepts the proposals for introduction of new characters but it is necessary to make serious research and persuade organization why these new characters should be accepted. As far as our letters are concerned, we were late in requesting special code positions for our letters and request was rejected, with explanation that they were just graphic variants of the same character for Unicode mainly does not deal with presentation of different variants of same character (glyphs) but only one representation form. The solution could be that a new codepage is made for us, but Unicode considers that it is not necessary to double the whole Cyrillic codepage just for a few cursive letters.
One type of solution may be found in new font format jointly developed by Adobe and Microsoft. It is Open Type format, based on Unicode standard which provides excellent typographic control and support for various languages. In one file it contains all characters predicted by Unicode table and apart from various alphabets there is extended private use area in which each font producer can introduce characters for a code points pursuant to its needs. Adobe Corporation standardized the private use area by predicting positions for many alternative forms of letters. Among other, there one can find characters for our Cyrillic cursive letters. They have names in the form of afiixxxxx, where xxxxx represents certain number and afii abbreviation of Association for Font Information Interchange. This was organization which International Standards Organization (ISO) appointed as relevant referential body for registration of new characters. Adobe started using AFII names for Cyrillic characters in Minion Cyrillic font, for it considered more practical and correct to use unique identification number from the existing base as the name of the character then to translate the names into English language. In time Adobe decided to name the characters pursuant to Unicode and AFII is abandoned but the names stayed and they are still used and recognized in software.
Open Type format enabled all these characters to find place in one font while earlier it was necessary to make special fonts (which belonged to the same typeface) not only for individual charset but for mentioned variations of the letterforms. Another favorable condition is that the format functions in the same way in different operation systems such as Mac and Windows.
To use Unicode and Open Type in the documents it is necessary to have software supporting them and relevant fonts.
Mac OS X, Windows 2000 and XP have installed support for work with Open Type fonts. However, for older versions of the operative systems additional software is necessary. When the surrounding does not provide full support for Unicode or Open Type fonts, the software can use only first 256 characters of font. The exceptions are Adobe applications such as InDesign for it has its own support for the work with this format independent from the operative system. InDesign even offers additional options for inserting characters which cannot be approached from Windows Character Map. Adobe Open Type Pro fonts usually have both Serbian and Russian Cyrillic and so we can always exchange Russian letters with ours. To approach those alternative characters the software we use for work must understand Open Type characteristics and provide the user with the environment from which he then can select those characteristics of the texts which suite him. InDesign can do it via already mentioned Glyphs palette and it also offers options for automatic replacement of certain letters with alternative forms, such as for example, the use of ligatures where it is enough to select that option and wherever ligature can be used InDesign will use it while we write the text.
As far as our letterforms are concerned we have to insert them manually by means of Glyphs palette but there are also scripts for InDesign which enable automatic replacement of Russian letterforms in the text with Serbian.
Regrettably, with the system keyboards today no one can reach our letterforms even when they exist in the fonts at proscribed code points of the private use area. The solution is localization where by selection of one language all other local characteristics will be supported. If that occurs at the system level, our letterforms would have their places in several standard fonts which are used in text processors and in Internet and probably, corresponding keyboard layout would be predicted as well. It is said that perhaps new Microsoft operative system Vista may have this option. For now, we can use scripts which do replacement of the characters in some software or we may modify foreign fonts by replacing Russian variants with ours and in domestic fonts define characters as to our own needs.
In short, there is less and less excuse today for application of Russian version of the letters instead of ours especially if the texts are processed in the fonts which contain our Cyrillic letterforms and which come in package with software supporting work with our letterforms. Technology development, knowledge spreading as well as care about our script may make Serbian Cyrillic in computers equal with other scripts.

There is a great difference in the layout of text written in Russian letters (upper part) and in our Serbian variant. Figure: font Resavska

ASCII standard contains 128 characters, 95 that are printable and 33 control ones which are not printable but are used for controlling the devices such as printers. Figure: font Verdana
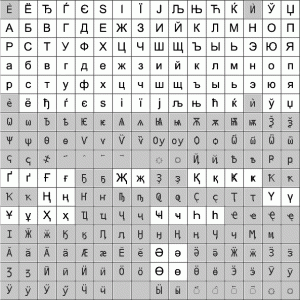
Cyrillic range in Unicode follows the ISO-8859-5 charset which can be seen at the next illustration Figure: font Arial

ISO-8859-5 standard contains characters for Bulgarian, Russian, Macedonian, Serbian, Belarus and Ukraine Cyrillic used till 1990. That year they reintroduced their specific letter g revoked by the Soviet decree of 1933. Figure: font Arial
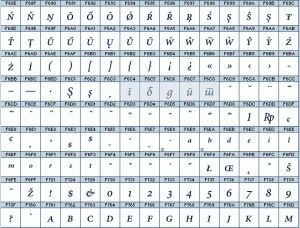
Part of Adobe private use area in Unicode table, our glyphs (shaded) are named as afii10063, afii10064, afii10192, afii10831, afii10832 and occupy the code positions from F6C4 to F6C8. Figure: font Minion Pro
LITERATURE
www.unicode.org
www.adobe.com/type

Vedran Erakovic was born in Split, Croatia and lives in Belgrade, Serbia. Vedran graduated in 2004 from the Faculty of Applied Arts, University of Arts, Belgrade, the Department of Applied Graphics where obtained his Master’s Degree in 2009. He works as an Assistant Professor of Calligraphy and Typeface Design at the Faculty of Applied Arts in Belgrade. He worked as an art director and graphic designer in the Serbian daily newspaper ‘Politika’, and also collaborated with FontShop from Berlin. He is involved in typeface design, calligraphy, graphic design, as well as newspaper and magazine design. He has participated in a lot of exhibitions and projects in his country and abroad and has won several awards for graphic and typeface design.
His PF Adamant Sans Pro is a modern sans serif font family that is the successor of the very successful PF Adamant Pro – award winner at the Granshan Awards 2014.